As AI-enabled sexual and reproductive health (SRH) chatbots rapidly expand across the Global South, the sector lacks standardized mechanisms to evaluate whether these tools are safe, effective, and responsive to users' needs. This project developed a practical framework for assessing the quality of chatbots designed to deliver SRH information to girls and young women.
Developed as a Columbia SIPA Capstone in partnership with Girl Effect, the research combined an extensive literature review, with expert interviews across artificial intelligence, sexual and reproductive health, digital design, and gender fields.
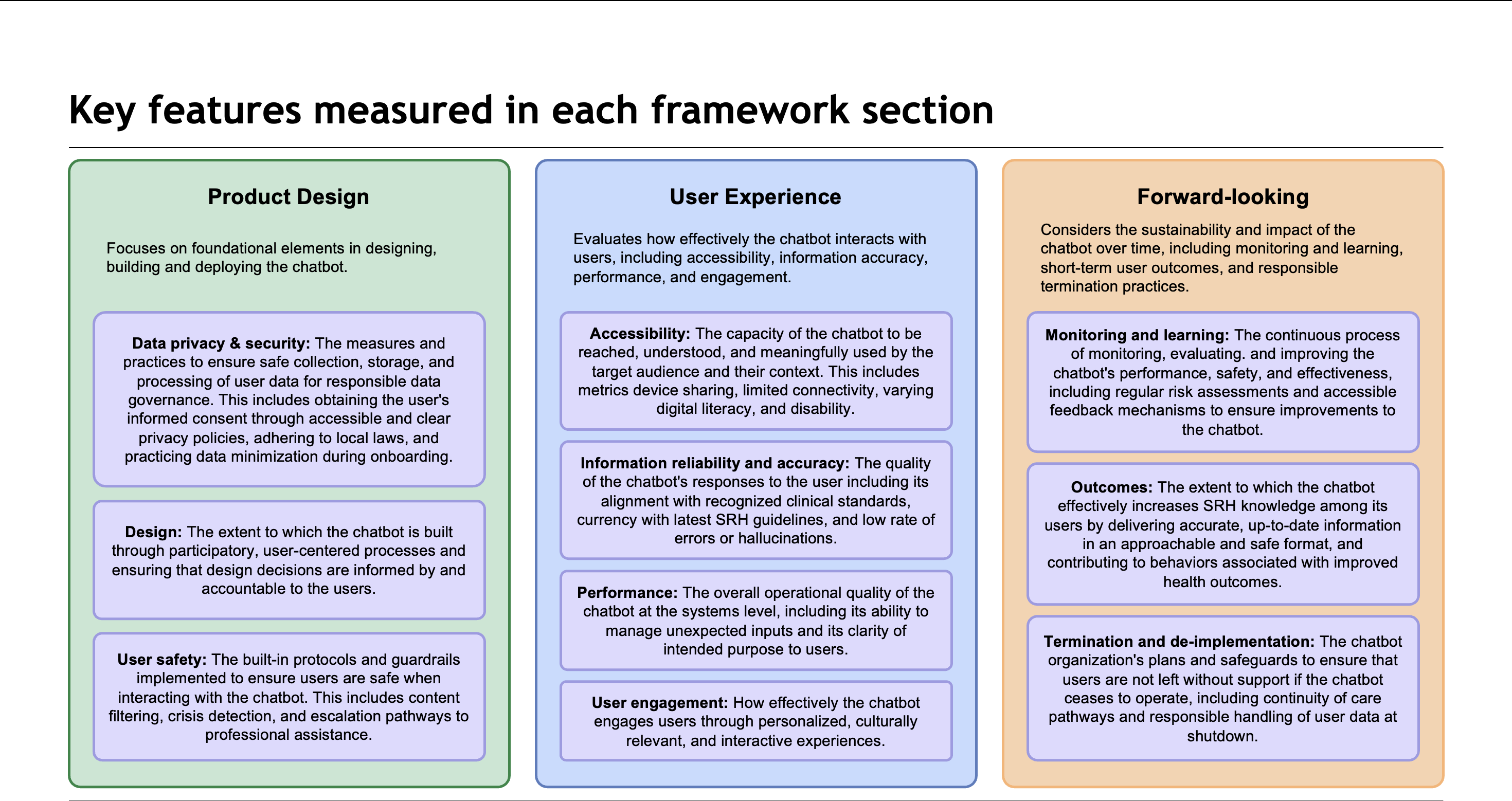
The resulting framework is structured around three high-level dimensions covering more than 30 weighted metrics:
Framework structure: Product Design covers data privacy, design, and safety; User Experience covers accessibility, information accuracy, performance, and engagement; Forward-Looking covers monitoring, outcomes, and termination planning.
Product Design focuses on foundational elements: data privacy and security, user-centered design, and safety protocols including crisis detection and escalation pathways.
User Experience evaluates how effectively the chatbot interacts with users, including accessibility for low digital literacy contexts, information reliability and accuracy against clinical standards, performance under unexpected inputs, and user engagement.
Forward-Looking indicators assess the sustainability and impact of the chatbot over time: monitoring and learning systems, short-term user outcomes, and responsible termination and de-implementation plans.
Only two out of five chatbots tested performed strongly across all evaluation domains. No chatbot was able to handle the full range of standardized test prompts without errors — all required follow-up clarifications at least once.
The comparative analysis of five SRH chatbots operating across the Global South revealed significant variation in performance. Chatbots generally performed strongest in user experience, while forward-looking metrics — feedback mechanisms, sustainability planning, and outcome monitoring — were consistently the weakest area across all case studies.

High-level case study assessment across Product Design, User Experience, and Forward-Looking dimensions. Green = High performance (>80%), Yellow = Medium (40-80%), Red = Low (<40%).
Safety performance was inconsistent, with only two chatbots scoring strongly across all safety indicators. Free-text chatbots offered smoother interactions than rule-based systems, but almost all lacked clear de-implementation plans for managing their user base and data in the event of program termination.
These findings underscore the urgent need for a shared quality benchmark for SRH chatbots. Chatbot developers should use human-centered design approaches and involve users in co-design from the outset. Funders should require that any SRH chatbot meets the framework criteria before receiving support.
The framework developed through this research offers a publicly available scorecard to support stronger evaluation, accountability, and user-centered design across the sector.